هندسة البيانات في Deriv: بناء بنية تحتية متينة

في عالم اليوم الذي يعتمد على البيانات، هل شعرت يومًا بالإرهاق من كثرة المعلومات أو بالإحباط بسبب غياب بنية تحتية موحدة وسهلة الوصول للبيانات؟
في Deriv، نحن نفهم هذه التحديات عن قرب. كوننا شركة تداول عبر الإنترنت، تُعتبر البيانات هي شريان الحياة الذي يغذي نجاح الشركة. مع معالجة هائلة تصل إلى 17 تيرابايت من البيانات يوميًا وأكثر من 600 مستخدم يقومون بتشغيل مئات الآلاف من استعلامات SQL شهريًا على لوحات تحليلات البيانات، يلعب فريق هندسة البيانات دورًا حيويًا في بناء وصيانة البنية التحتية المتينة التي تُدير عمليات Deriv المعتمدة على البيانات.
تمامًا كما تعتمد المدينة المزدحمة على بنيتها التحتية لتعمل بسلاسة، يعمل فريق هندسة البيانات في Deriv كنقطة محورية مركزية، يربط مصادر البيانات المختلفة ويضمن توافر المعلومات في الوقت المناسب للأقسام المختلفة.
هذا الاعتماد على البيانات يمتد حتى جوهر عمليات Deriv. من تحليل قيمة عمر العميل وتقسيم قاعدة عملائنا إلى كشف الاتجاهات الطويلة الأمد ضمن بياناتنا التاريخية الغنية، تمكننا بياناتنا من اتخاذ قرارات مستنيرة. في هذه المقالة، نغوص في كيف تُمكّننا عمليات هندسة البيانات من تحقيق اتخاذ قرارات سريع ودقيق عبر المنظمة.
بنية منصة بيانات Deriv
منصة بيانات Deriv هي نظام بيئي مصمم بشكل جيد يدمج مصادر بيانات متنوعة، بما في ذلك قواعد البيانات العلائقية، APIs، والملفات الخارجية، ضمن مستودع بيانات مركزي. تُظهر هذه البنية، الموضحة في مخطط التدفق، كيفية السماح بمعالجة البيانات وتخزينها واستهلاكها بكفاءة عبر المنظمة.
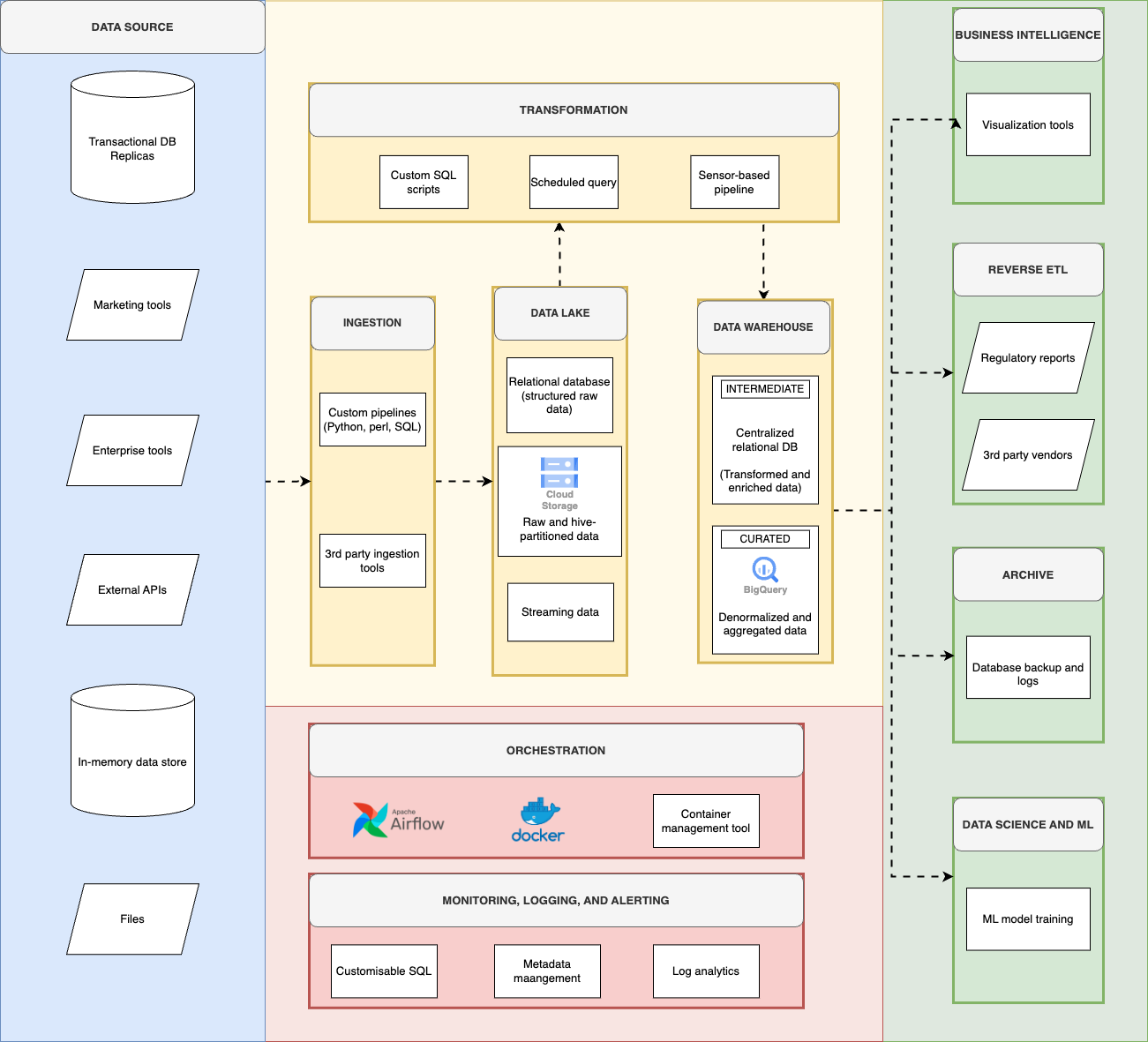
أساس منصة البيانات لدينا: مصادر البيانات الرئيسية
يستمد نظام بيانات Deriv من مجموعة متنوعة من المصادر، تمامًا مثل شبكات البنية التحتية المتعددة في المدينة. يدير فريق هندسة البيانات جمع ودمج البيانات من قواعد البيانات العلائقية، APIs، والملفات الخارجية ببراعة، مما يضمن أساس بيانات شامل وموثوق.
تنسيق سير العمل: الاستفادة من DAGs في airflow
لأتمتة وتبسيط خطوط بياناتنا، يستخدم فريق هندسة البيانات لدينا Airflow، أداة قوية لتنظيم سير العمل. يمكنك التفكير بها كنظام تحكم مروري لطرق بياناتنا السريعة. تساعد الرسوم البيانية الموجهة غير الدورية (DAGs) في Airflow على جدولة وإدارة تنفيذ مختلف مهام معالجة البيانات، مما يضمن توصيل البيانات في الوقت المناسب للفرق المختلفة. تمامًا كما تختلف أنماط المرور طوال اليوم، تتحدث بعض جداول بياناتنا بيانات المنتج يوميًا، في حين تلتقط الأخرى أنشطة دخول المستخدمين في كل دقيقة وحتى بيانات التداول في الوقت الفعلي.
نظام إدارة قواعد البيانات العلائقية
لتقليل الانقطاعات في العمليات التجارية الرئيسية، يستخدم فريق هندسة البيانات نسخاً للقراءة وأدوات إدارة التكوين عند العمل مع قواعد البيانات العلائقية. تُوضح هذه الطريقة، كما في الشكل 2، كيف يحافظ الفريق على تكامل وموثوقية البيانات أثناء دمجها بسلاسة في مستودع البيانات. يشبه الأمر وجود شبكة طاقة احتياطية تضمن استمرارية العمليات حتى أثناء الصيانة أو الترقيات.

كيفية ملء مستودع البيانات
تستخدم Deriv نظامي مستودع بيانات: قاعدة بيانات علائقية مركزية وGoogle BigQuery. قبل تحميل البيانات إلى BigQuery، يتم عادةً معالجة البيانات في قاعدة البيانات العلائقية المركزية، حيث تُطبق التحويلات والتجميعات باستخدام دوال SQL. يشبه هذا تنقية المواد الخام قبل إرسالها إلى مصنع لمزيد من المعالجة.
في BigQuery، يقوم الفريق بإنشاء أسواق بيانات من الاستعلامات المجدولة، والتي تغذي أدوات التصور، وتقارير التنظيم، ونماذج التعلم الآلي. يمكن اعتبار هذه الأسواق مخازن متخصصة داخل المنشأة الأكبر، كل منها يلبي احتياجات محددة.
لماذا نحتاج إلى قاعدة بيانات علائقية حتى الآن
تلعب قاعدة البيانات المركزية العلائقية دور الوسيط بين مصادر البيانات وBigQuery. بحكم تواجدها على نفس الشبكة مع نسخ قواعد البيانات المعاملاتية للقراءة، يمكن للفريق الوصول إلى البيانات بسهولة. تُعالَج البيانات على دفعات، ويتم تنقيحها وتحويلها إلى المخططات المقابلة. يشبه ذلك منطقة تجهيز حيث تُصنّف البضائع وتُعدّ للشحن إلى وجهاتها النهائية.
لتحقيق استيعاب البيانات شبه الفوري في مستودع البيانات المركزي، يستخدم الفريق وحدة وصول بيانات عن بُعد مخصصة للاستعلام المباشر من نسخ القراءة دون الحاجة إلى سكربتات من جهة المصدر. هذا يتيح تحديثات أسرع للبيانات، مثل خدمات التسليم السريع التي تتجاوز طرق الشحن التقليدية.
Google BigQuery: مستودع بيانات سحابي قابل للتوسع
الطبقة التالية في مستودع البيانات هي BigQuery. اخترناها للأسباب التالية:
- البنية بدون خادم: لا نحتاج للقلق بشأن إدارة الموارد عند تنفيذ الاستعلامات. تخزينه العمودي مُحسّن لأعباء العمل التحليلية، حيث يمسح مجموعات أعمدة متناثرة بكفاءة. يشبه ذلك وجود سيارة ذاتية القيادة تتكيف مع ظروف المرور وتحسن مسارها لتحقيق أقصى كفاءة.
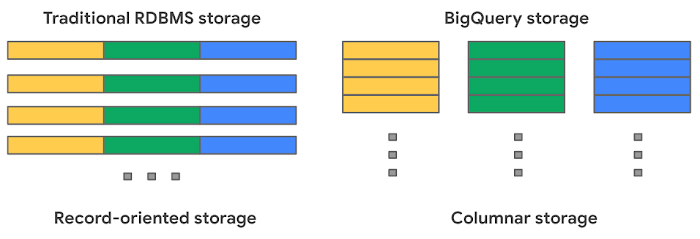
- إدارة الأذونات بسهولة: نضمن أن يحصل كل فريق على وصول فقط إلى البيانات ذات الصلة باستخدام خدمة إدارة الوصول المدمجة. يشبه ذلك وجود أنظمة تحكم دخول آمنة في المبنى، تمنح الدخول فقط للأشخاص المصرح لهم.
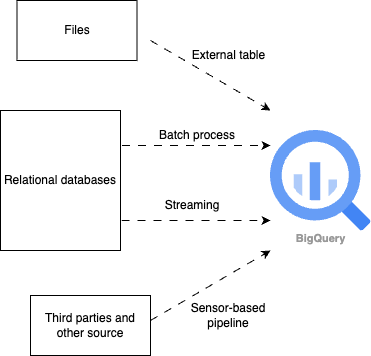
شحن البيانات: طرق متعددة لتحميل BigQuery
نستخدم طرقًا مختلفة لتحميل البيانات إلى BigQuery:
- المعالجة على دفعات: يقوم الخط الأنبوبي بتحميل دفعات من الملفات المُعدة من التخزين السحابي إلى جداول BigQuery لفترة زمنية مجدولة محددة. يشبه ذلك شحنات البضائع المجدولة التي تصل في أوقات محددة.
- المعالجة المستمرة: نستخدم API البث لمعالجة البيانات في الوقت القريب من الحقيقي. يشبه ذلك تغذية أخبار مباشرة يتم تحديثها باستمرار بأحدث المعلومات.
- المحفزات القائمة على الأحداث والجداول الخارجية: يقوم خط الأنابيب المعتمد على المستشعرات بمعالجة الملفات الجديدة التي ترد في دلاء التخزين السحابي، مطبقًا التحويلات ويشغّل منطق الخط المناسب. يشبه ذلك جهاز استشعار الحركة الذي يُشغل إنذارًا عندما يدخل شيء جديد مجال رؤيته.
- جداول BigQuery الخارجية: الوصول إلى البيانات من الملفات في التخزين الخارجي. يشبه ذلك الوصول إلى الملفات من خادم بعيد.
في عالم اليوم المدفوع بالبيانات، هل شعرت يومًا بالارتباك من حجم المعلومات الهائل أو بالإحباط بسبب عدم وجود بنية تحتية موحدة وسهلة الوصول للبيانات؟
بناء بنية تحتية قوية للبيانات واستخدام أدوات البيانات القوية هو المفتاح لأن تصبح منظمة مدفوعة بالبيانات. اكتشف كيف تفعل Deriv ذلك.
تعظيم القيمة: استراتيجيتنا في نموذج تسعير BigQuery المزدوج
لتقليل التكاليف، تستخدم Deriv نموذجين للتسعير في BigQuery: الدفع عند الطلب، الذي يحسب تكلفة كل استعلام بناءً على عدد البايتات الممسوحة، ونموذج السعة، الذي يستخدم أماكن الحوسبة المحجوزة.
يُستخدم نموذج الدفع عند الطلب لخطوط أنابيب إدخال البيانات والاستعلامات المجدولة، بينما يُستخدم نموذج السعة للاستعلامات العارضة، ولوحات البيانات، والتقارير.
يضمن هذا الفصل أن تقارير الاستخدام العارض لا تتداخل مع تنفيذ خط أنابيب البيانات الأساسي، كما يتيح تحكمًا أفضل بتكاليف الاستعلام. يشبه ذلك وجود خطة دفع حسب الاستهلاك وخطة اشتراك شهرية لهاتفك، حسب نمط استخدامك.
أدوات مراقبة البيانات: نهجنا في تسجيل الدخول، التنبيه، والمراقبة
فكر في نظام مراقبة صحي يتتبع العلامات الحيوية لديك وينبهك لأي مشكلات محتملة. بنفس الطريقة، نراقب الخط الأنبوبي بحثًا عن مشكلات مثل تعطل الخادم، شذوذات البيانات، أو الأخطاء، لضمان موثوقية بياناتنا ونظامنا.
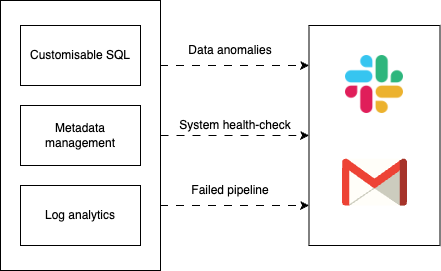
إليك بعض الطرق التي نراقب بها نظامنا:
- لوحات بيانات SQL قابلة للتخصيص لرصد عدم انتظام البيانات في مقاييس العمل. تشبه هذه اللوحات عدادات لوحة تحكم السيارة، حيث توفر معلومات في الوقت الفعلي عن أداء النظام.
- تحليلات السجلات لمراقبة الحالات والتنبيه عن أي خطوط أنابيب فاشلة. يشبه ذلك وجود صندوق أسود يسجل كل ما يحدث في النظام، مما يتيح لنا التحقيق في أي حوادث.
- إدارة البيانات الوصفية لتتبع التغيرات في البيانات داخل نظامنا. يشبه ذلك وجود نظام تحكم بالإصدار يتتبع التغييرات في المستندات عبر الزمن.
نتكامل مع مزودي البريد الإلكتروني وSlack لتلقي إشعارات من أدوات التنبيه لدينا حتى نُبلغ فورًا بأي مشاكل حرجة ونتخذ إجراءات سريعة.
جودة البيانات: الحفاظ على سلامة البيانات عبر الأنظمة
يُعد الحفاظ على جودة البيانات أمرًا حيويًا لـ Deriv. أنشأ الفريق خط أنابيب جودة بيانات مخصص لفحص التكرارات وضمان تناسق أعداد البيانات عبر مستودعات البيانات. في قاعدة البيانات المركزية، نستخدم قيود المفاتيح الأساسية والفريدة، بينما بالنسبة لـ BigQuery التي تفتقر إلى مفاتيح أساسية مفروضة، أنشأنا جدول بيانات وصفية يحدد أعمدة المفاتيح الأساسية. بالإضافة إلى ذلك، ندقق حجم البيانات عبر الطبقات، لضمان تطابق عدد السجلات التي تم استيعابها في BigQuery مع تلك الموجودة في الطبقة الأولى من قاعدة البيانات العلائقية لجميع الجداول يوميًا.
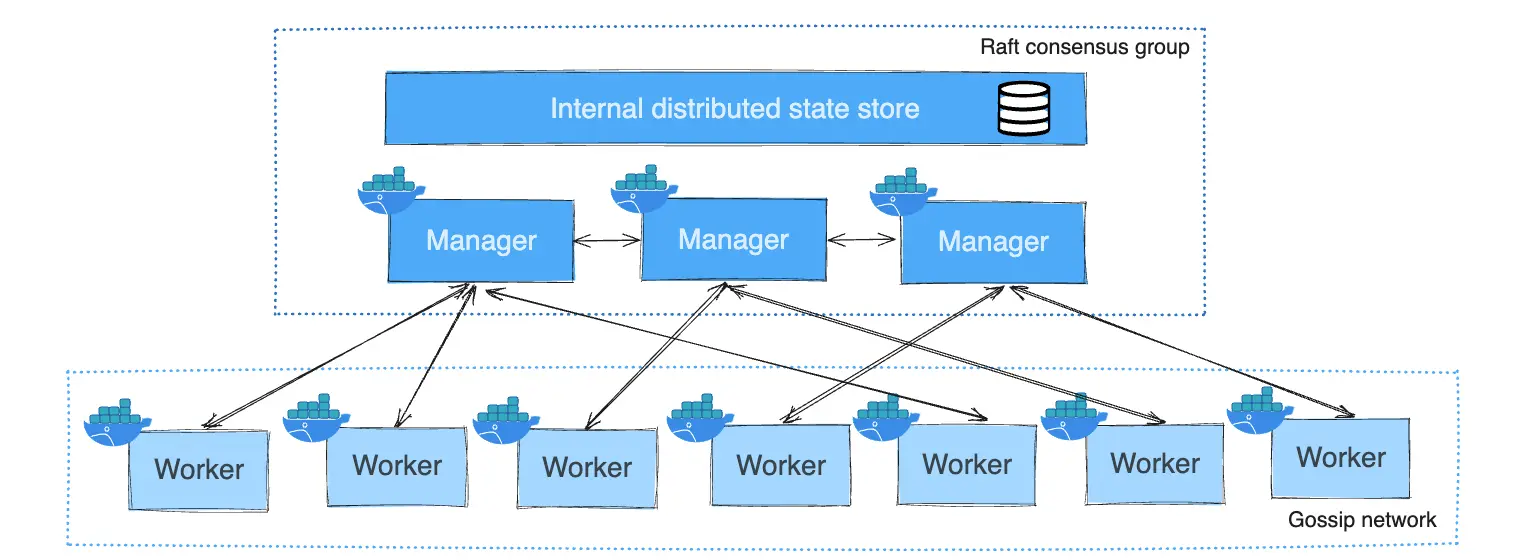
حاويات Docker: نشر التطبيقات الرئيسية في حاويات
نقوم بنشر التطبيقات في مجموعة Docker باستخدام برنامج إدارة الحاويات. يتيح لنا ذلك إدارة نشر الحاويات، والشبكات، والحجوم، وأدوات الاعتماد، وتوسيع النطاق عبر الحواسيب. تحديث إصدار خدمة docker يتطلب فقط تعديل ملف docker-compose.yml وإعادة النشر، مع إمكانية التراجع بسهولة إذا لزم الأمر. يشبه ذلك وجود مكعبات بناء مُصنّعة مسبقًا يمكن تجميعها وتفكيكها بسهولة، مما يسمح بالبناء المرن والفعال.
أفضل ممارسات الأمان: ضمان إدارة بيانات آمنة
نحافظ على بيئات مراجعة وإنتاج منفصلة، كل منها بتكوينات شبكية فريدة. تتيح لنا بيئة المراجعة اختبار التغييرات بأمان قبل نشرها في الإنتاج، ما يقلل من المخاطر. بالإضافة إلى ذلك، نطبق المصادقة الثنائية للوصول إلى خدماتنا، مما يوفر طبقة أمان إضافية.
نقوم بتحديث قاعدة الكود والبنية التحتية لدينا بانتظام وفقًا لأفضل ممارسات الأمان. يقوم فريق مخصص بتدقيق الثغرات، تحديث الأدوات، تدوير بيانات الاعتماد، وإيقاف الأنظمة القديمة. يخضع الوصول إلى البيانات لمبدأ أقل الامتيازات داخل كل قسم، مع كون السياقات الإضافية، مثل معلومات التعريف الشخصية (PII)، تتطلب موافقة محددة.
دور هندسة البيانات في تشكيل مستقبل Deriv المبني على البيانات
يركز فريق هندسة البيانات لدينا على بناء بنية تحتية للبيانات تدمج مصادر بيانات مختلفة في مستودع البيانات. تضمن ممارسة تسجيل الدخول، والمراقبة، وأفضل ممارسات الأمان جودة البيانات وموثوقيتها.
بينما قد تتغير التفاصيل في هذه المقالة من حين لآخر، يظل التزامنا الأساسي بتسهيل اتخاذ قرارات سريعة ودقيقة ثابتًا. نُقدّر ملاحظاتكم ونشجعكم على مشاركة آرائكم حول استراتيجيتنا.
حول المؤلف
فوزان راغيتيا هو مهندس بيانات في Deriv يمتلك شغفًا للتعلم المستمر. يقوم بتوسيع خبرته باستمرار في تحليلات البيانات وبنية بيانات البنية التحتية.
















